I Hate Reading Big Text
A reflection on an old project and some of the side-effects it had.
In 2016, I was deep into University life. I lived and breathed it and I was constantly thinking about ways I could solve my University problems. During the summer break, I decided to learn front-end web development. This opened up opportunities for me to create mini webpages and tools to solve my own problems. This post looks at one such project and the side effects that came from it.
University sometimes requires you to read a long research paper, usually in the form of a PDF document. The text of the paper is often crammed into a 2-column layout with tiny text. The actual content is often self-referential. For example, “Let us define a pdq as an fdr that contains one or more synodes.”
I don’t find this style of content particularly easy too read; I’ll often have to scroll back up to check what a definition refers to, or pause to think about it and look away from the screen. “What exactly is an fdr, again?”
Then, after I recall the information I needed, I scroll, I have lost my place in the document and end up wasting time reading sentences that I have already read.
 I don’t think this style of content is very easy to read. Why don’t research papers have bigger text?
I don’t think this style of content is very easy to read. Why don’t research papers have bigger text?
I had also recently been introduced to reveal.js - a slideshow library in JavaScript. A plan formed in my head.
What if we read the text from a PDF, processed it to figure out what the individual sentences were, and then create a slideshow with one sentence per slide? This would prevent the ‘eye tracking failure’ as the text now isn’t as dense. Then, for scientific texts, what if we analyse the text to figure out where the definitions and sections are? We could create a glossary/contents page hybrid. Add a ‘back’ button to ease navigation and those papers should be easy to read!
I set about building it. Mozilla have a fantastic library for interpreting PDFs (which is waaaay more challenging than I had imagined) and for converting it to text, I used some code that I shamelessly stole from StackOverflow. I then found a library that detects the sentence boundaries called SBD. Finally, piping that text into the aforementioned reveal.js created something pleasing. Give it all a barebones UI page so that you can actually use it and we have out prototype. (I later replaced reveal.js with custom code for reasons that aren’t altogether clear to me on reflection.)
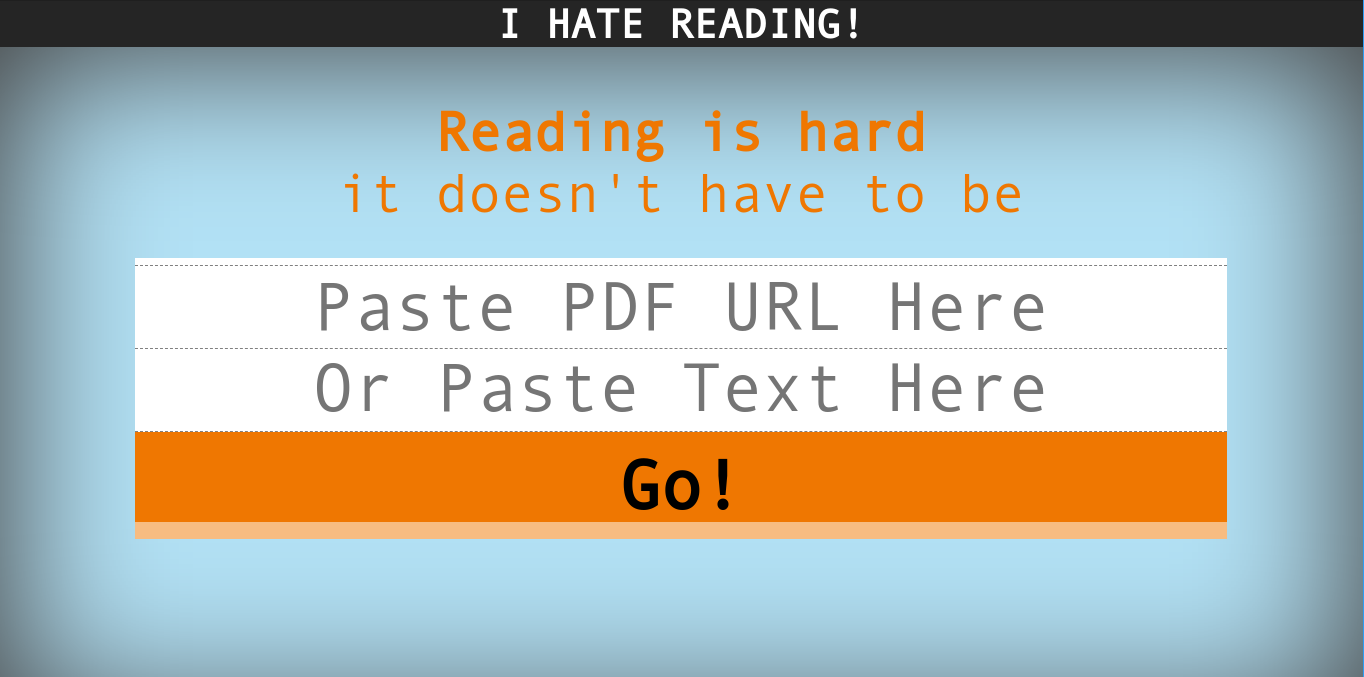 User Interface of I Hate Reading.
User Interface of I Hate Reading.
(Incidentally, I set up a Heroku Dyno running cors-anywhere so that the tool can download PDFs from anywhere.)
But there was a problem. Sentences don’t have fixed length! I could have a short sentence of just a few words which would look very silly on a large page, or I could have a long sentence that overflows the page. Clearly I needed a solution to dynamically resize text to be as large or small as it needs to be to fill the textbox.
 Long text overflows the screen when dynamic resizing is not used.
Long text overflows the screen when dynamic resizing is not used.
Enter bigtext-jquery.js - a library that does exactly that. I liked the demos on the website, but I didn’t like the jquery dependency. I looked at the source code and determined that jquery wasn’t doing anything that couldn’t be done just as easily with plain javascript. The code was MIT licensed, so I set about replacing the jquery in the code, producing bigtext.js! I tested the code locally by reproducing their demos and everything seemed fine.
Eagerly, I introduced it to my site… oh.
 Bigtext makes text as big as it can be… to fit on a single line inside the container.
Bigtext makes text as big as it can be… to fit on a single line inside the container.
Bigtext only makes the text as big as it can be to fit on a single line, which isn’t what we want here.
I searched again and found jquery-textfill.js, a library which seemed, this time, to do what I desired. Instead of spending lots if time removing that pernicious JQuery dependency, I bit the bullet and loaded JQuery into my codebase.
…and it worked! The site - at least everything I had built to this point - worked pretty much as I had imagined.
 Textfill resizes the text to a font-size that perfectly fits the container.
Textfill resizes the text to a font-size that perfectly fits the container.
It takes a little bit of getting used to (because the text keeps changing size), but I found that it made it simple for me to read complex texts - though it struggles to parse Research Papers, my original goal.
The summer ended shortly after, and I never really took the opportunity to work on it again. Today, three years later, it still mostly works, though the touch functionality seems to be a little buggy on modern phones.
Now what about bigtext.js? Well, eager to make my work available to the world, I published it to NPM and on Github. Not knowing much about the javascript ecosystem (I had only learned javascript that summer), my code worked by adding a .bigtext() function to the prototype for HTMLElement ![]() . I didn’t know that doing that was non-grata, and I later found that my code was forked to create big-text.js (well… kinda. The git repository has no commits by me. But then I did the same thing to DanielHoffmann…
. I didn’t know that doing that was non-grata, and I later found that my code was forked to create big-text.js (well… kinda. The git repository has no commits by me. But then I did the same thing to DanielHoffmann… ![]() ) to replace the prototype function with a module export of a regular function. Okay, sure.
) to replace the prototype function with a module export of a regular function. Okay, sure.
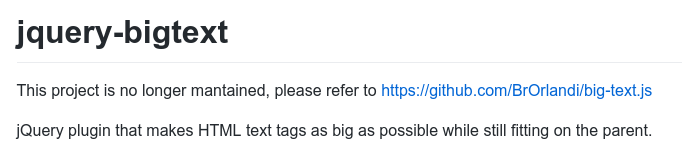
The nice thing is that the original bigtext-jquery.js is now no longer maintained, and has a message pointing to big-text.js (the fork of my version) as the official version!
For me, this is sort of the best of both worlds. I like knowing that my work was important to creating the current official repository (in fact I doubt it wouldn’t exist if not for my effort!), and I like that I don’t have to expend the effort to be the maintainer of it.
I have need of the functionality of jquery-textfill.js again for one of my upcoming projects, so maybe I will give it the bigtext treatment and get to work removing that jquery dependency…
P.S. I'm late to the party, but I recently got a twitter account that you can follow here.