License over HTTP
A look at the problems of licenses online, with a proposed solution.
I’m always quite cautious about content created by others when I develop software or publish things online. The legal world is too messy for me, I hate that I could be sued for using something incorrectly or misunderstanding something, and the licensing documents don’t make things any easier by being so impenetrable. The world of photographs and graphics is a great microcosm of using content created by others, so it serves as a good topic to discuss.
If I’m writing a blog post and I want to illustrate something but don’t have a suitable picture that I have taken myself, then I need to source one, and I either look on Pixabay, or search using Google’s usage rights selection.
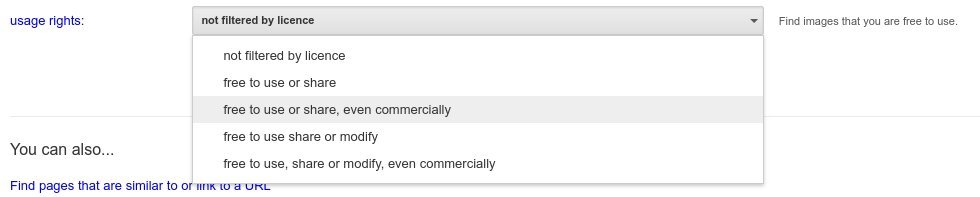 Google’s “usage rights” advanced search feature is very useful for finding permissively licensed content.
Google’s “usage rights” advanced search feature is very useful for finding permissively licensed content.
Pixabay is great because not only does it always list exactly what license the image has, but usually the images there can be used with no attribution required, which is great. A lot of the time I also find images from Flickr too (via Google, but it’s possible to search with filtered licenses on Flickr directly). Flickr images also have their license information visible - the ones I find via Google are often permissive but with an attribution requirement. I try quite hard to follow these requirements - I might make some errors, misunderstand, or forget something sometimes - but overall I think I follow them.
License Blues
A big problem I have with licenses is that I find it quite hard to incorporate proper attribution into my webpages. It’s easy if I want to use the image inline - I can just put the attribution as both the alt-text and caption for the image. But what if I use an image that requires attribution as a background? I don’t have a mechanism to display that attribution, so I avoid those images. It’d be great if I had a way of displaying this license without impacting my page layout.
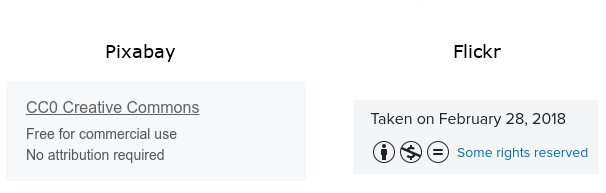 Websites doing licensing well.
Websites doing licensing well.
Sites like Flickr and Pixabay are great because they tag the image in a consistent way, indicating exactly what the usage rights are. But what about the (arguably) most popular image host, like Imgur? There’s no license tagging there. If I want to use one of those images, I don’t know if I can do anything with it. How about the images from much smaller pages - perhaps similar to my website? Sometimes, I’ll find an image online that I’d love to use, but it has no associated license that I can see. Or maybe I can’t find the proper source to ask their permission. This shuts down my attempt to use the content, which is unfortunate, as I’d love to share it and even link back to the creator.
Similarly, maybe I captured a picture, and then uploaded it to my website - perhaps I would be okay with people using the images I have taken for their own purposes. To give that permission, I’d have to add license clutter to every image on my website. It’d ruin my interface trying to distinguish between pictures that I have taken myself and pictures I sourced from elsewhere. I don’t want every image to have to have visible licensing information, as it would get in the way and might even reduce the meaning that I am trying to convey through using the images!
Let’s pretend I did add a caption to every image, describing exactly the license implications. This still wouldn’t really solve the problem fully - people who saw the image on my site would know what they could do with my content, sure, but it’s not in a machine readable format, so bots from places like Google probably wouldn’t. I assume Google have custom handlers written to find the image licensing metadata from sites like Flickr and Pixabay. My site isn’t big enough for Google to bother writing one of those, so people wouldn’t be able to find my content in Google’s results even though I have this permissive licensing caption.
So there are three main issues with licenses and displaying someone elses content online:
- Displaying licensing information everywhere is difficult from a UI perspective. It’s ugly, and distracts from the real purpose of the page.
- Licensing information isn’t connected to the content it refers to - it is less readable for machines and therefore not as indexable, less reusable and less useful.
- It can be hard to find the original source for an image, especially if it gets republished by someone who don’t care so much for sources and licenses.
Legislative Issues
I recently saw this blog post from GitHub, about how new proposed EU legislation will require online services to filter content uploaded to their servers for copyrighted content. If you try to upload copyrighted content, services will be required to block it, no questions asked.
Aside from the huge issues for all programmers that GitHub’s post highlighted, the proposed legislation would also cause issues for content publishers. My site is hosted via GitHub, so this new EU legislation would have some interesting implications for me.
I try to follow the requirements of licensed work, adding attribution where necessary, avoiding restrictively licensed content, etc. But even if I follow it perfectly, automated filters have no way of knowing that. The automated filters would most look at the images I am uploading in isolation, seemingly unassociated with the markup. If I rehost an image that has an attribution requirement, and I satisfy that on the page that I link to it from, these automated filters have no way of knowing that it was properly attributed. So these filters would just see the ‘violating’ file and filter it. Not great.
Worse, if these filters function similarly to how YouTube’s ContentID system, then there are a whole host of problems. ContentID is too dumb to correctly detect fair use and parody, which I experienced once when I edited a video game footage that my friend and I had recorded. I included a two-second clip of audio from a popular song, continuing a parody (or maybe meme) of a comically bad song choice, and the whole video that I had edited got flagged - really very silly for a 2 second gag.
There’s really no way that these filters can work flawlessly. The internet is too chaotic and freeform. DMCA takedowns work because there is a human in the loop who can impartially evaluate. Automatic filters will never have a powerful enough reasoning capability for this application. It can’t work. It can’t even begin to work if it can’t even detect when I have followed the correct license procedure, or detect parody.
False Friends
Images and audio have had a ‘solution’ to this problem for a long time - JPEG and WAV files can have EXIF data, which gives the metadata for the file, including the licensing information.
jetroid@netricsa:~/pictures$ exif jetslicensedpicture.jpg
EXIF tags in 'jetslicensedpicture.jpg' ('Intel' byte order):
--------------------+----------------------------------------------------------
Tag |Value
--------------------+----------------------------------------------------------
Image Width |3264
Image Length |2448
Manufacturer |SAMSUNG
Model |GT-I9100
Copyright |©Copyright Jet Holt, 2018. All rights reserved.
In theory, for the supported file types, you could accurately track the copyright/license information and source of a file through the EXIF data. In practice though, when you upload to an online service, they’ll strip the EXIF data. This is unfortunate, but is quite important, as EXIF data can commonly lead to privacy leaks. How many times has someone been doxxed on 4chan by uploading an image that they took with location enabled?
So image metadata is not the solution.
The Solution
A novel-ish solution for this problem - and the reason I wanted to write this article - is that there’s already a machine readable way of telling us about the metadata of any file that we recieve through the internet. A mechanism that we use every day, even if we don’t realise it. In fact, you used it to view this page, and it told your browser all sorts of information. Sound familiar?
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 15999
Last-Modified: Sun, 25 Mar 2018 19:32:35 GMT
Date: Sun, 25 Mar 2018 19:32:38 GMT
Connection: Keep-Alive
HTTP response headers are the perfect way to give image license information, and I’m honestly really surprised it isn’t already used - there isn’t a commonly used tag for it.
Here’s how I could see it working:
HTTP/1.1 200 OK Content-Type: text/html; charset=utf-8 Content-Length: 19957Content-Creator: Jet Holt Content-Original-Source: https://jetholt.com/licenses-over-http/ Content-License: CC-BY-NC-SA v3.0 Content-License-Source: https://creativecommons.org/licenses/by-nc-sa/3.0/Last-Modified: Sun, 25 Mar 2018 19:32:35 GMT Date: Sun, 25 Mar 2018 19:32:38 GMT Connection: Keep-Alive
Now, obviously, you need to store this extra metadata separately to the actual image or content - but websites like Imgur already store metadata about their images. They store the creator, the title, the description, the comments, etc. Why not the source, copyright, and license information?
Karl Dubost at Otsukare.com had a similar idea, leveraging a proposed standard for the HTTP ‘Link’ tag. That solution is equally good and solves exactly the same problem, just in a slightly different proposed execution.
Benefits:
- A bot can simply view the HTTP header to determine license, and doesn’t have to sift through HTML data to find the license. This massively simplifies things for the bot. It’s faster, too, as you can simply request the HEAD for the file during the HTTP request.
- I can provide license information without having to clutter up my website design and layout.
- If given a direct link to an image (eg: https://jetholt.com/assets/images/content/bartos-flur-electronics-project.jpg), then you can determine the copyright and your usage rights without having to find the source of the image or any pages that link to it.
- You can track down the original source (if known by the hosting site), so that you can ask them some more things, see similar works, etc.
{kind=link}
Drawbacks:
- Doesn’t properly solve the problem of the EU’s censorship bots flagging uploaded content, as data isn’t necessarily coupled with the data during upload. You could add it to the request header during the upload, though! Then the censorship bots could accurately determine license information.
- Probably goes against the spirit of attribution if you only attribute using a HTTP header. The purpose of attribution requirements is to give props to the original creator, generate them search engine popularity and linkback traffic, etc. You’re not doing any of those things if your attribution is in a piece of data that the average user is never going to see.
- If your hosting is outsourced (as with my site, which uses GitHub and Cloudflare), then you have limited control over your HTTP response headers, and you might not be able to set them yourself.
P.S. I'm late to the party, but I recently got a twitter account that you can follow here.